
Gender Bias in AI Generated Images
Are different genders fairly represented when generating images using OpenAI's Dall-E-2 text-to-image platform?
Background
Introduction
Since the invention of the multi-layer perceptron network, there has never been a time when AI has been more prevalent or visible in our society than the present day. Machine learning is used for almost everything; healthcare, business analytics, correctional systems, scientific exploration, and even in seemingly mild and light hearted applications that have achieved widespread commercial and critical success. One of these applications is the image generating model known colloquially as ‘DALL-E 2’, a software that receives prompts in the form of natural language and outputs its own perception of what the user wants to see. At first glance this seems completely fangless and friendly. However, as other investigations have demonstrated, this is clearly and concisely not the case.
OpenAI has recently come under fire for the racial and gender make-up of its outputs when given specific prompts. This is a problem, and one that they have apparently been working to address.
OpenAi's claimed bias mitigation techniques as of July 2022

In this project, we will investigate just how far the team at OpenAI has come in terms of bias mitigation by examining the outputs of several different prompts that have been passed through their image generation software.
Methods
-
Step 1:
Occupations were chosen based on their proximity to having demographic parity in the workplace. For workplace demographic data, the US Bureau of Labor Statistics (BLS) and specifically their ‘Labor Force Statistics from the Current Population Survey’. was used. Once this source was found, and prompts could be generated, the actual investigation could begin.
-
Step 2:
In order to calculate sample sizes, a one-sample dichotomous outcome formula was used. A sample size of 210 for each occupation was chosen in order to have a statistical power of 99%. Due to technical and budget limitations, only ten occupations were chosen.
Five of those occupations were selected as female-dominated while the remaining five were selected as male-dominated as according to the BLS data from step 1.
The table below shows the ten occupations selected as prompts for DALL-E 2 along with the number of BLS survey respondents and the percentage of non-male respondents
Occupation N % Non-Male Financial/Investment Analysts 387 40.2 Janitors/Building Cleaners 2183 40.2 Lawyers 1141 38.5 Cooks 2012 38.4 Dentists 140 36.6 Bartenders 457 59 Biological Scientists 110 57.9 Secondary School Teachers 1000 58.7 Pharmacists 375 59.6 Trainers/Fitness Instructors 234 62.9 -
Step 3:
For each occupation selected, 210 images where generated and stored with a filename associated with its occupation. The images were then manually labeled by all group members and given a final label based on the majority consensus.
Below are sample images for images generated with the labels: cook, financial analyst, secondary school teacher, and bartender.




-
Step 4:
For each occupation a hypothesis test was done as follows:- H0: The images generated from DALL-E 2 for this occupation follows demographic parity
- H1: The images generated from DALL-E 2 for this occupation do not follows demographic parity
Results
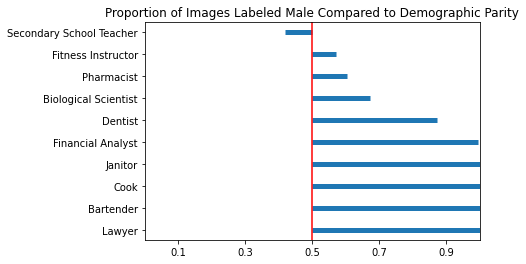
P-values shown below demonstrate that DALL-E 2’s api is biased, at least across the axes of occupation and gender:
| Occupation | Observed Proportion | P-value |
| Financial/Investment Analysts | 1 | < 1e-6 |
| Janitors/Building Cleaners | 1 | < 1e-6 |
| Lawyers | 1 | < 1e-6 |
| Cooks | 1 | < 1e-6 |
| Dentists | 0.87 | < 1e-6 |
| Bartenders | 1 | < 1e-6 |
| Biological Scientists | 0.67 | < 1e-6 |
| Secondary School Teachers | 0.42 | 0.022592 |
| Pharmacists | 0.60 | 0.002961 |
| Trainers/Fitness Instructors | 0.57 | 0.04494 |
Conclusion
Through our work, our group has proven the existence of significant occupational gender bias in OpenAI’s DALL-E 2 model. Several prompts did not even generate a majority female-presenting response, even when the data obtained from the BLS indicated that the profession was female dominated. While the impacts of such extreme bias may not be immediately apparent, as the model begins to see more widespread use across various applications, the impacts will likely grow more severe and visible. As such, OpenAI should move to address the bias present in their algorithms as soon as possible, before they see widespread commercial use.
DSC 180B: Winter 2023
James Dai, Vedan Desai, Moses Oh, Costin Smilovici, Tyler Tran
James Dai, Vedan Desai, Moses Oh, Costin Smilovici, Tyler Tran